Планировщик
Есть 3 модели для нарезания вычислений на потоки:
-
N:1 - несколько пользовательских потоков запущено на едином потоке ядра операционной системы. Преимущество - осуществляется очень быстрое переключение контекстов, но нет возможности воспользоваться многоядерностью.
1:1 - каждый поток выполнения совпадает с одним потоком операционной системы. Он использует все ядра автоматически, но переключение контекста происходит медленно, потому что требует прерываний работы операционной системы.
-
Go пытается взять лучшее из обоих с помощью М:N планировщика. При этом произвольное число Go-рутин M планируется на произвольное количество потоков N операционной системы. Получается одновременно быстрое переключение контекста + возможность воспользоваться всеми ядрами в вашей системе. Основным недостатком данного подхода является сложность его включения в планировщик.
GMP Model
Планировщик Go использует 3 сущности:
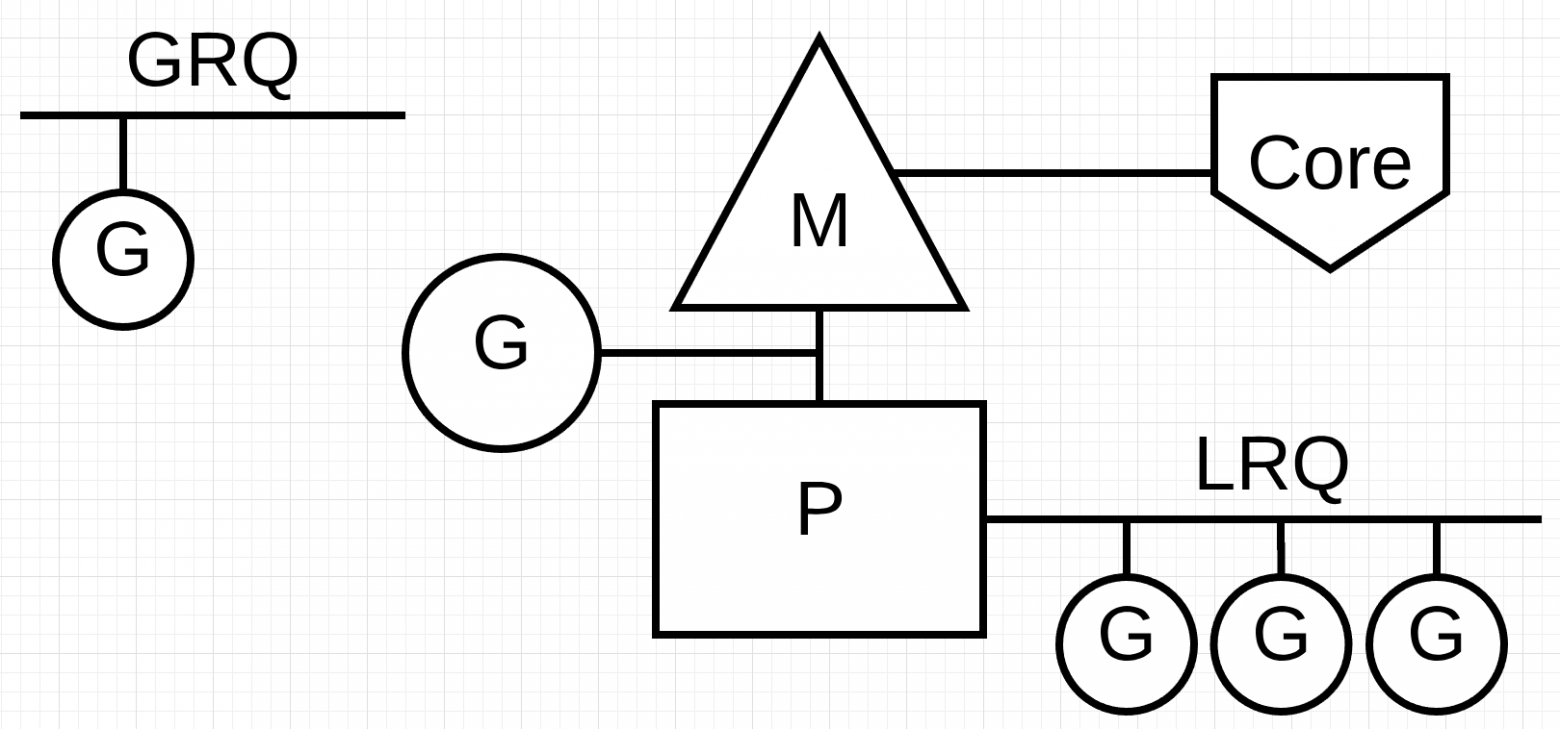
M Machine(Треугольник) thread операционной системы. Точнее абстракция над ним, в go runtime представлена в виде структуры. Выполнением такого потока управляет операционная система, и работает это во многом подобно стандартным потокам POSIX.
- M создаются по мере необходимости (но ограничены
GOMAXPROCS). - Если горутина блокируется в
syscall, создается новый M. - System Monitor завершает неиспользуемые M через
forcegc(чтобы не накапливались лишние потоки).
G Goroutine(Круг). Он включает стек, указатель команд и другую важную информацию для планирования горутины, такую как канал, который на ней может быть блокирован.
P Processor(Прямоугольник) Планировщик на ядре. Можно понимать как локальную версию планировщика c собственной очередью горутин под конкретный M c каким-то контекстом(регистры и т.д).
Local and Global Queues
В планировщике Go есть две разные очереди выполнения:
-
глобальная (GRQ)
-
локальная (LRQ) - может хранит до
256горутин (FIFO) однако, есть такая оптимизация, что последняя горутина, может выполнится первой, без очереди, одноэлементный стэк LIFO. Это сделано потому, что, есть ненулевая вероятность, того что на M контекст выполнения соотвтетсвует тому, что нужен именно этой горутине, поэтому часто имеет смысл выполнить её вперёд остальных.
Каждому P присваивается LRQ, который управляет горутинами, назначенными для выполнения в контексте P. Эти горутины по очереди включаются и выключаются из контекста M, назначенного для этого P. GRQ предназначен для горутин, которые не были назначены для P. Существует процесс, чтобы переместить горутины из GRQ в LRQ
runtime.schedule() {
// only 1/61 of the time, check the global runnable queue for a G.
// if not found, check the local queue.
// if not found,
// try to steal from other Ps.
// if not, check the global runnable queue.
// if not found, poll network.
}
-
С вероятностью 1/61 немедленно проверить GRQ и запустить горутиную оттуда. 61 выбрано чтобы число не было слишком низким, что приводило бы к чрезмерно частой проверке глобальной очереди выполнения, и не слишком высоким, чтобы не привести к голоданию горутин в GRQ.
-
приоритетнее запускать G в своем собственном LRQ
-
затем из LRQ других P. Воруется
1/2локальной очереди другого(случайного) P (по умолчанию,128из256возможных). Это называется work-stealing и противопоставляется work-sharing. Интересная деталь: work-stealing в Go не очень агрессивен, поэтому иногда загрузка ядер может быть неравномерной. -
затем из GRQ
-
затем из netpoller.
Если горутины нет, поток засыпает (park()), а System Monitor позже его разбудит.
Sysmon
sysmon(системный монитор) – это фоновый поток, который выполняет служебные задачи Go Runtime. Он не выполняет горутины, а следит за состоянием системы, работой вашего приложения и помогает справиться с узкими местами, с которыми может столкнуться ваша программа. Не связан ни с одним P, M или G в нашей модели.
-
Обнаруживает
M, зависшие вsyscall- Если
Mзавис вsyscall>10ms,sysmonзапускает новыйM, чтобыPне простаивал. - Когда
syscallзавершается,Gвозвращается в очередь, аMлибо продолжает работать, либо паркуется.
- Если
-
Обслуживает
NetPoller-
Обрабатывает неблокирующие I/O (
net,epoll,kqueue,IOCP). Т.е чекает сетевые события (epoll/kqueue/IOCP) и пробуждаетG, ждущие данные.Перемещает горутины из netpoller в глобальную очередь, если они живут там больше 20мс
-
-
Пробуждает
P, если он долго простаивает- Если
Pничего не делал >10ms,sysmonдаёт ему работу из глобальной очереди.
- Если
-
Запускает
forcegc(форсированный GC)- Если горутины долго не доходят до
runtime.GC(),sysmonзапускает его принудительно.
- Если горутины долго не доходят до
Как sysmon управляет M, зависшими в syscall?
Допустим, G делает блокирующий syscall, например, read().
Mблокируется, выполняяsyscall.Pотвязывается(handoff) отM, чтобы не простаивать и ищет новыйM.- Если свободного
Mнет,sysmonсоздаёт новыйM, чтобыPпродолжил работу. - Когда
syscallзавершится,Mне возвращается к своемуP, а отправляет горутину в глобальную очередь. - Далее
Mлибо продолжает работать, если есть свободныйP, либо паркуется.
SysMon также не учитывается в планировщике Go. Он всегда запущен, но достаточно умен, чтобы не потреблять ресурсы, когда нечего делать. Время его цикла динамично и зависит от текущей активности выполняемой программы.
Любая горутина, выполняющаяся более 10 мс, помечается как вытесняемая (мягкое ограничение). Поэтому планировщик Go может решить, следует ли вернуть ее в LRQ или продолжить выполнение в потоке.
Netpoller
В отличие от syscall, который блокирует M, NetPoller позволяет G ждать данные без блокировки M.
NetPoller – это слой абстракции над системными API для асинхронного I/O(epoll/kqueue/IOCP)
Когда G делает net.Conn.Read(), Go не блокирует M, а:
- Регистрирует сокет в
NetPoller(epoll/kqueue). - Переключает
Gв состояние_Gwaiting. Pпродолжает выполнять другиеG, аMне простаивает.- Когда данные поступают,
sysmonпробуждаетGи ставит её в очередь_Grunnable.
В результате M остаётся свободным, можно обслуживать тысячи G на одном M.
Т.е Когда горутина ждет сетевой запрос (например, ожидает на узле), она добавляется в NetPoller. Таким образом, горутина не блокирует основной поток ядра. Вместо этого она терпеливо ожидает в очереди NetPoller, позволяя другим горутинам свободно выполнятся.
Взаимодействие sysmon и NetPoller
sysmonкаждые 10 мс проверяетNetPoller.- Если есть активные события (
epoll_wait/kqueue_wait),sysmonпробуждает горутины. - Это позволяет обрабатывать сетевые соединения без блокировки
M.
Тип многозадачности
Бывает вытесняющая и кооперативная.
С не кооперативной (вытесняющей) многозадачностью все прекрасно знакомы на примере планировщика ОС. Данный планировщик работает в фоне, выгружает потоки на основании различных эвристик, а вместо выгруженных процессорное время начинают получать другие потоки.
Для кооперативного планировщика характерно другое поведение — он спит пока одна из горутин явно не разбудит его с намеком о готовности отдать свое место другой. Планировщик далее сам решит, надо ли убирать из контекста текущую горутину, и если да, кого поставить на ее место. Примерно так и работал планировщик GO.
в GO 1.14 изменился принцип работы планировщика, рассмотрим причины по которым эти изменения были сделаны. Взгляните на код:
func main() {
runtime.GOMAXPROCS(1)
go func() {
var u int
for {
u -= 2
if u == 1 {
break
}
}
}()
<-time.After(time.Millisecond * 5) // в этом месте main горутина разбудит планировщик, а он в свою очередь запустит горутину с циклом
fmt.Println("go 1.13 has never been here")
}
Если скомпилировать его с версией GO < 1.14, то строчку go 1.13 has never been here вы на экране не увидите. Происходит это потому, что, как только планировщик дает процессорное время горутине с бесконечным циклом, она всецело захватывает P, внутри этой горутины не происходит ни каких вызовов функций, а значит и планировщик мы больше не разбудим. И только явный вызов runtime.Gosched() даст нашей программе завершиться.
Раньше runtime.Gosched использовал safe-points места, где точно можно вызвать планировщик без боязни, что мы попадем в атомарную для GC секцию кода. Как мы уже говорили, данные safe-points располагаются в прологе функции (но далеко не каждой функции, заметьте). Если вы разбирали go-шный ассемблер, то могли бы возразить — никаких очевидных вызовов планировщика там не видно. Да это так, но вы можете найти там инструкцию вызова runtime.morestack, а если заглянуть внутрь этой функции то обнаружится вызов планировщика.
Раньше планировщик, в моменте когда решал что горутина выполняется слишком долго выставлял ей свойство stackguard а уже сама горутина проверяла его, и отдавала управления, если видела, что был запрос на это дело.
С версии 1.14 используется ОС сигнал SIGURG для того, чтобы прервать горутину, которая занимает слишком много времени.
@todo расписать про safe point
Состояния горутин (G):
Горутина в Go может находиться в одном из следующих состояний:
_Gidle (Неактивная)
Горутина не используется (ещё не запущена или завершилась и ожидает переиспользования). Обычно такие структуры g находятся в пуле горутин (freelist), откуда их можно переиспользовать.
_Grunnable (Готовая к выполнению)
Горутина готова к запуску, но ещё не выполняется. Она находится в очереди выполнения у P (локальной) или в глобальной очереди планировщика.
_Grunning (Выполняется)
Горутина активно выполняется на одном из M (потоков ОС). В этот момент планировщик не может её прервать, пока не произойдёт блокирующая операция.
_Gwaiting (Ожидание)
Горутина заблокирована и ждёт внешнего события:
- Synchronization calls – Синхронизационные вызовы (атомарные операции, мьютексы, операции с каналами, системные вызовы).
- Asynchronous calls – Асинхронные вызовы (сетевые вызовы).
- Asynchronous calls – Long-running – Долговыполняющиеся вызовы
- Ожидание
sync.Mutex. time.Sleep()- ожидание в
select {}.
В этом состоянии горутина не находится в очереди выполнения, пока не получит сигнал от события.
_Gsyscall (Системный вызов)
Горутина выполняет блокирующий системный вызов, например:
-
Чтение/запись в файл (
os.Open(),os.ReadFile()). -
Сетевые операции (
net/http,net.Dial()). -
Разница с
_Gwaiting: тут блокируется поток ОС (M), поэтому Go Runtime может создать новыйM, чтобы продолжить выполнение других горутин.
_Gdead (Завершена)
Горутина завершилась (return, panic или runtime.Goexit()). Её структура (g) может быть переиспользована для новых горутин.
_Gcopystack (Перемещение стека)
Горутина меняет размер стека, потому что стек в Go динамический (начинается с 2 KB и растёт при необходимости). Это временное состояние, когда Go копирует стек горутины в новую область памяти.
Как это работает?
- Горутина создаётся (
newproc()) и становится_Grunnable. Pставит её в локальную очередь.Mзабирает её и запускает →_Grunning.- Если
Gблокируется (syscall, ожиданиеchanи т. д.) →_Gsyscallили_Gwaiting. - Когда
syscallили ожидание завершается → горутина возвращается в_Grunnable. - Если горутина завершилась →
_Gdead, и память под неё чистит GC.
Что делает park()?
Функция park в Go Runtime используется для остановки (заморозки) текущего M (потока ОС), когда у него нет активных горутин. Она является частью внутреннего механизма планировщика .
Когда M паркуется?
-
Остановка потока
M, когда у него нет работыЕсли
M(поток ОС) выполнил все доступные горутины и в системе больше нет задач, он "паркуется" (переходит в спящее состояние) до тех пор, пока не появится новая работа. -
Блокировка
Mво времяsyscallКогда
Mвыполняет блокирующий системный вызов, напримерread(),write(), то Go Runtime может перевестиMвparkи переключиться на другой поток. -
Остановка
Mпри уменьшении количества потоков (GOMAXPROCS)Если значение
GOMAXPROCSуменьшается, некоторыеMмогут стать избыточными и Go Runtime отправит их вpark.
Как это выглядит?
Mпонимает, что у него нет работы.Mвызываетpark(), освобождая ресурсы ОС.- Если появится новая работа,
PразбудитMчерезruntime.notewakeup().
Что делает handoff()?
Функция handoff() используется, чтобы переназначить P другому M, если текущий M заблокировался (syscall).
Функция handoff() в Go используется внутри планировщика для передачи P от одного M другому. Это необходимо, когда поток M заблокировался ожидая syscall и планировщик хочет, чтобы работа G не простаивала.
Как это работает?
G1выполняется наM1(привязан кP1).G1вызываетsyscall,M1блокируется (_Gsyscall).handoff()отвязываетP1отM1и даёт его другомуM2.M2теперь выполняет горутиныP1.- Когда
syscallзавершится,M1отправитG1в глобальную очередь.
В Go Runtime решение о том, делать немедленный handoff (открепление потока от M и передача P другому M) или оставить поток заблокированным, принимает системный монитор (sysmon) и логика планировщика.
Когда вы вернетесь из handed-off syscall , планировщик Go выполнит следующие действия:
- Если старый
P(тот, с которого был передан поток) доступен, горутина будет назначена в егоLRQ - Если старый
Pне доступен, горутина будет привязана к любому свободному процессору. - Если нет свободных процессоров, горутина будет добавлена в глобальную очередь выполнения.
Кто создаёт новую горутину?
Горутины создаются с помощью go func(), что вызывает runtime.newproc().
Алгоритм newproc():
- Берёт
PтекущегоM, на котором выполняетсяgo func(). - Выделяет новый объект
G, инициализирует его стек и состояние. - Добавляет
Gв локальную очередьP, если есть место. - Если локальная очередь
Pзаполнена (256G), некоторыеGсбрасываются в глобальную очередь.
Что работает в обход GMP?
В Go есть несколько аспектов, которые могут выполняться в обход GMP-модели:
-
GC (Garbage Collector) — сборщик мусора выполняется в отдельном потоке, и хотя он использует планировщик Go, он может делать это в фоновом режиме, не связанный напрямую с планированием горутин. В процессе работы GC может вмешиваться в планирование, например, при необходимости приостановить выполнение горутин, чтобы выполнить сборку мусора.
-
NetPoller — это отдельная часть планировщика, который управляет сетевыми операциями (например, асинхронными I/O операциями). Он может работать вне контекста стандартных горутин, особенно при обработке событий с использованием системных вызовов, таких как poll или epoll на Linux.
-
Sysmon — это фоновая горутина, которая выполняется для мониторинга системных процессов, включая работу с таймерами, очистку ресурсов и сбор информации о состоянии системы.
-
Программное окружение (runtime environment) — некоторые части Go runtime, такие как управление стеками и кучей (например, переподключение горутин при увеличении стека), также выполняются в фоновом режиме и могут не подчиняться полной GMP-модели.
Таким образом, несмотря на то, что основная часть работы Go-среды основывается на GMP-модели, есть несколько фрагментов кода, которые работают в фоновом режиме, не имея прямой связи с ней, таких как GC, NetPoller и sysmon.
Дополнительно:
-
https://habr.com/ru/users/not91/publications/articles/
-
https://habr.com/ru/articles/333654/
-
https://habr.com/ru/articles/502506/