Sharding (Шардинг)
Шардинг — прием, который позволяет распределять данные между разными физическими серверами. Процесс шардинга предполагает разнесения данных между отдельными шардами на основе некого ключа шардинга. Связанные одинаковым значением ключа шардинга сущности группируются в набор данных по заданному ключу, а этот набор хранится в пределах одного физического шарда. Это существенно облегчает обработку данных.
Шардинг можно рассматривать как частный случай партиционирования. Партиционирование(partitioning, также секционирование) — это разбиение таблиц, содержащих большое количество записей, на логические части по неким выбранным администратором критериям. Партиционирование таблиц делит весь объем операций по обработке данных на несколько независимых и параллельно выполняющихся потоков, что существенно ускоряет работу СУБД. Для правильного конфигурирования параметров партиционирования необходимо, чтобы в каждом потоке было примерно одинаковое количество записей.
Например, на новостных сайтах имеет смысл партиционировать записи по дате публикации, так как свежие новости на несколько порядков более востребованы и чаще требуется работа именно с ними, а не со всех архивом за годы существования новостного ресурса.
Самая важная и сложная задача, возникающая при шардинге – поиск и выборка данных. Способ поиска зависит от того, как они шардированы. Наша цель состоит в том, чтобы самые важные и часто встречающиеся запросы затрагивали как можно меньше секций. В этом плане очень важно выбрать ключ (или ключи) секционирования данных. Ключ шардирования определяет, в какую секцию попадает та или иная строка. Если известен ключ шардирования некоторого объекта, то можно ответить на два вопроса:
- Где следует сохранить данные?
- Где найти запрошенные данные?
Запросы к нескольким шардам хуже, чем к одному, но если они затрагивают не слишком много шардов, то все еще не так плохо. Самый худший случай – когда у вас нет ни малейшего представления о том, где находятся данные, и приходится просматривать все шарды без исключения.
Выбор ключа шардирования
Обычно хорошим ключом секционирования является идентификатор какой-нибудь важной сущности в базе данных. Такие сущности называются единицами шардирвания (unit of sharding). Например, если информация секционируется по идентификатору пользователя или клиента, то единицей секционирования является соответственно пользователь или клиент.
Если модель данных сложна, то и секционировать ее труднее. Во многих приложениях существует более одного ключа секционирования, особенно если в данных можно выделить несколько важных «измерений». Иными словами, приложение должно иметь возможность эффективно взглянуть на информацию под разными углами зрения и получить целостное представление. Это означает, что некоторые данные придется хранить в двух разных видах.
Распределение данных
Существует два основных способа распределения данных по секциям: фиксированное и динамическое. Для обеих стратегий необходима функция секционирования, которая принимает на входе ключ секционирования строки и возвращает номер секции, в которой эта строка находится. Здесь слово «функция» употребляется в математическом смысле как отображение множества входных значений (области определения) во множество выходных значений (область значений), такую функцию можно реализовать разными способами, в том числе с использованием справочной таблицы в базе данных.
Фиксированное распределение
Для фиксированного распределения применяется функция разбиения, которая зависит только от значения ключа секционирования. В качестве примеров можно привести деление по модулю или хеш-функции. Такие функции отображают значения ключей секционирования на конечное число «ячеек» (buckets), в которых хранятся данные. Пусть имеется всего 100 ячеек и требуется найти, в какую из них поместить пользователя 111. С применением деления по модулю ответ ясен:остаток от деления 111 на 100 равен 11, поэтому пользователь должен находиться в секции 11.
Однако у этой стратегии есть и недостатки.
- Если секции велики и их немного, то балансировать нагрузку между ними будет сложно.
- При фиксированном распределении вы лишены возможности решать, куда помещать конкретную запись, а это важно в приложениях, где нагрузка на единицы секционирования неравномерна. Некоторые части данных используются гораздо чаще, чем остальные, и когда такие обращения по большей части адресуются к одной и той же секции, стратегия фиксированного распределения не позволяет снять нагрузку, переместив часть данных в другую секцию. Эта проблема не так серьезна, если элементы данных малы, но их количество в каждой секции велико; закон больших чисел все расставит по своим местам.
- Как правило, изменить алгоритм секционирования сложнее, потому что требуется перераспределить все существующие данные. Например, если секционирование производилось делением по модулю 10, то имеется 10 секций. Когда приложение вырастет, и секции станут слишком большими, возникнет желание увеличить их количество до 20. Но для этого придется перехешировать все заново, обновить очень много данных и перераспределить их по новым секциям.
Динамическое распределение
Альтернативой фиксированному распределению является динамическое распределение, описание которого хранится отдельно в виде отображения единицы секционирования на номер секции. Примером может служить таблица с двумя столбцами: идентификатор пользователя и идентификатор секции:
CREATE TABLE user_to_shard (
user_id INT NOT NULL,
shard_id INT NOT NULL,
PRIMARY KEY (user_id)
);
Функцией разбиения служит сама таблица. Зная ключ секционирования (идентификатор пользователя), можно найти соответствующий номер секции. Если подходящей строки не существует, можно выбрать нужную секцию и добавить строку в таб лицу. Впоследствии сопоставление можно будет изменить, потому стратегия и называется динамической.
Table functions – это когда у вас просто какой-то config. Использование подходов Table functions к шардингу очень тесно завязано на таком понятии как virtual bucket. Вспомните, у вас есть функция отображения ключа на шард. Представьте себе, что у вас посередине появляется некое промежуточное отображение, т.е. это отображение превращается в два. Сначала вы отображаете ключ на некоторый виртуальный bucket, потом виртуальный bucket – на соответствующую координату в пространстве вашего кластера.
Существует не очень много методов это все сделать. А еще мы помним о том, что самое главное – это дать свободу и удобство работы системному администратору. Виртуальные bucket-ы, как правило, выбираются в достаточно большом количестве. Почему они виртуальные? Потому что на самом деле они не отражают реального физического сервера. И используется несколько методов для отображения непосредственно ключа на шард.
Один метод – это когда первая часть «key to bucket» function – это просто какой-то хэш или консистентный хэш, т.е. какая-то часть, которая определяется по формуле, а bucket непосредственно на шард отображается через config. Вторая вещь более сложная – когда вы и то и то отображаете через config. Более сложная, потому что вам, условно говоря, для каждого ключа нужно еще помнить, где он лежит. Вы приобретаете возможность передвинуть любой ключ куда угодно, но с другой стороны вы теряете возможность легко и быстро, имея просто маленький config в «bucket to shard», из ключа определить bucket и потом пойти достаточно быстро пойти в нужное место.
С динамическим распределением связаны определенные накладные расходы, так как требуется обращение к внешнему ресурсу, например серверу каталогов (узлу, на котором хранится отображение). Для поддержания приемлемой эффективности такая архитектура часто нуждается в дополнительных слоях программного обеспечения. Например, можно использовать распределенную сис тему кэширования, в памяти которой хранятся данные с сервера каталогов, которые на практике изменяются довольно редко. Основное достоинство динамического распределения – более точное управление местом хранения данных. Это упрощает равномерное разделение данных по секциям и позволяет гибко адаптироваться к непредвиденным изменениям.
Кроме того, динамическое распределение дает возможность выстраивать многоуровневую стратегию шардировани поверх простого отображения ключей на секции. Например, можно организовать двойное отображение, при котором каждой единице секционирования сопоставляется некоторая группа (например, группа членов клуба книголюбов), а сами группы по возможности размещаются в одной секции. Это позволяет воспользоваться преимуществами близости шардов и избегать межсекционных запросов. Динамическое распределение дает возможность создавать несбалансированные секции. Это полезно, когда не все сервера одинаково мощные или когда некоторые серверы используются еще и для других целей, например для архивирования данных. Если при этом имеется еще и возможность в любой момент перебалансировать шарды, то можно поддерживать взаимно-однозначное соответствие между секциями и узлами, не растрачивая впустую емкость дисков. Некоторым нравится та простота, которая свойственна хранению в каждом узле ровно одной сек ции (но не забывайте, что имеет смысл делать шарды относительно небольшими). Динамическое распределение позволяет организовать стратегию секционирования любой сложности, фиксированное такого богатства выбора не предоставляет.
Комбинирование динамического и фиксированного распределений
Можно также применять комбинацию динамического и фиксированного распределения. Это часто бывает полезно, а иногда даже необходимо. Динамическое распределение хорошо работает, когда отображение не слишком велико. С ростом количества единиц секционирования его эффективность падает.
В качестве примера рассмотрим сис тему, в которой хранятся ссылки между сайтами. В ней необходимо хранить десятки миллиардов строк, а ключом секционирования является комбинация исходного и конечного URL. На любой из двух URL могут быть сотни миллионов ссылок, поэтому ни один URL по отдельности не является достаточно избирательным. Однако невозможно хранить все комбинации исходного и конечного URL в таб лице сопоставления, поскольку их слишком много, а каждый URL занимает много места.
Одно из возможных решений – конкатенировать URL и написать хеш-функцию, отображающую получившиеся строки на фиксированное число ячеек, которые затем можно динамически отображать на шарды. Если количество ячеек достаточно велико, скажем, миллион, то в каждый шард их можно поместить довольно много. В результате мы получаем многие преимущества динамического секционирования, не заводя гигантскую таблицу отображения.
Поиск данных
Самых распространенных метода – три:
Умный клиент
Представьте себе, что у вас есть табличная функция, которая использует маппинг ключа на bucket. Используется какой-то хэш, какая-то формула. Затем у вас есть некоторый config, который состоит из всего лишь небольшого количества данных, например, 1000 маппингов, 1000 строк, 1000 соответствий ключ-значение. В результате это все где-то зашито в вашем клиенте. Ваш клиент получил ключ, сразу определил, на какой сервер идти, и сразу пошел на этот сервер.
В принципе, хороший метод, самый простой и самый клевый. За одним исключением – в случае, если у вас разрастается инфраструктура, и вам в какой-то момент нужно задевелопить кучу других каких-то клиентов, на других языках, для других приложений, то вам нужно повторить эту логику – это во-первых. Во-вторых, если вам нужно сделать каким-то образом решардинг, и сделать это с нулевым maintenance subwindow, то это сделать довольно сложно, потому что вся логика – в процессах приложений, которые сейчас работают. Каким-то образом вам надо сигнализировать, что что-то сейчас будет меняться, карта такая-то будет становиться другой и т.д. Все это, в общем, достаточно сложно.
Прокси
Представьте себе, что прокси делает следующее: он принимает запрос, как будто к одной ноде, вернее, как будто к одному приложению, и клиент просто не знает о том, что на самом деле за этим прокси есть много нод.
Какая-то логика применяется внутри прокси, он определяет, на какую ноду идти, делает запрос, получает данные, потом передает эти данные назад клиенту. Это очень удобно, хотя бы потому, что ничего специально учить не надо, разговаривать можно как с одной базой, как мы привыкли, и если у нас есть какие-то клиентские приложения, которые уже написаны, нам их переписывать не надо.
Жирные стрелочки на этом слайде указывают, где потекли данные. Например, видно, что жирные данные текут уже в два места. Одно место – это между прокси и, собственно, нодой данных. Другое место – это между прокси и клиентом. Для больших производительных систем это является неким дополнительным условием, которое надо иметь в виду – удвоение трафика внутри площадки.
Прокси перегружается. Вы увеличиваете их количество. Прокси выходят из строя, у вас появляется еще одна точка отказа. Решение неидеальное, но какой еще потенциальный профит у этого решения? Вы в прокси можете также заниматься load balancing-ом, вы можете смотреть, какие ноды у вас вышли из строя, т.е. автоматически определять, делать failover полностью прозрачным для прокси. Т.е. прокси позволяет сделать логику приложения очень простой.
Есть некий способ упростить всю эту технологию, если сделать так, чтобы прокси работала на том же хосте, на котором работает само приложение. Проблема прокси – вы должны распространять состояние шардинга, т.е. прокси должны знать, где какой ключ находится. И тут мы приходим к следующей технологии, которая упрощает именно эту историю – технологии вынесения этого состояния в единое место – в координатор.
Координатор
Координатор – это вещь, похожая на предыдущие (т.е. клиент, по- прежнему, ничего не знает), но совершенно другая. Координатор – это просто такой классный парень, который очень быстро отвечает на простые вопросы «Куда мне идти?». Получает маленькую порцию вопросов, т.е. длина вопроса небольшая, быстро дает ответ, после этого клиент сам устанавливает соединение и идет на нужную дата-ноду. Здесь преимущество заключается в том, что у вас убирается сложность прокси.
Эта архитектура обладает определенными проблемами. Если координатор вдруг упадет, то все пропало. Но с другой стороны, координатор – вещь крайне простая и ее очень легко резервировать через асинхронный мастер-мастер, даже мастер-слэйв.
Перераспределине данных(решардинг)
При необходимости можно переместить данные из одной секции в другую, чтобы сбалансировать нагрузку. Например, многие читатели, наверное, слышали, как разработчики больших сайтов фотогалерей или популярных социальных сетей рассказывали о своих инструментах перемещения пользователей в другие секции. Способность перемещать данные открывает целый ряд возможностей. Например, чтобы модернизировать оборудование, можно перенести всех пользователей из старой секции в новую, не останавливая секцию целиком и не переводя ее в режим чтения.
Однако мы стараемся по возможности избегать перебалансирования, так как это может вызвать приостановку обслуживания. Из-за перемещения данных становится сложнее добавлять в приложение новые функции, поскольку их приходится учитывать в сценариях перебалансирования. Если секции не слишком велики, то прибегать к этому, возможно, и не понадобится; часто для балансирования нагрузки достаточно перенести секцию целиком, а это гораздо проще, чем перемещать часть секции (и более эффективно, если говорить о стоимости в расчете на одну строку данных).
Один из подходов – «update is a move». Идея следующая – всегда, когда вы меняете кокой-то ключ, вы его неявно двигаете. Допустим, у вас ключ шардинга – это, собственно, ключ шардинга и timestamp. Когда вы меняете данные, вы меняете timestamp, и он у вас естественным образом оказывается на другом шарде. Вы можете в какой-то момент закрыть апдейты на определенный шард и рано или поздно просто его вывести из строя. Т.е. очень просто передвигать данные, очень просто выводить данные из строя.
Второй подход – «data expiration». В нем просто добавили несколько серверов, явно не решардили, данные естественным образом заэкспайрились – получилась новая схема шардинга. Этот же подход можно использовать где угодно, где вы можете старые данные просто удалять. Тогда вы новые данные льете на новые ноды или закрываете какие-то старые ноды. Данные сами собой просто постепенно переезжают.
Здесь ключевым моментом являются части – горячая и холодная. Автоматически появляются на вашем кластере горячая и холодная части, и может оказаться, что если вы неправильно подобрали какие-то конфигурации или веса, то горячая часть будет очень маленькой, и число серверов, которые вам нужно постоянно добавлять для того, чтобы поддерживать горячую часть (например, если это на twitter или выборы Обамы)...
Консистентный хэш
Способ создания распределенных хеш-таблиц, при котором вывод из строя одного или более серверов-хранилищ не приводит к необходимости полного переразмещения всех хранимых ключей и значений. Консистентное хеширование позволяет перераспределять только те ключи, которые использовались удаленным сервером или которые будут использоваться новым сервером. Таким образом, в случае выхода из строя одного узла, ключи не просто переходят на следующую ноду, а равномерно распределяются по нескольким следующим нодам.
Идея простая, возьмем окружность и будем рассматривать ее как интервал на котором определена хеш-функция функция. Применив хеш-функцию к набору ключей (синие точки) и серверов (зеленые точки) сможем разместить их на окружности. Для того чтобы определить на каком сервере размещен ключ, найдем ключ на окружности и будем двигаться по часовой стрелке до ближайшего сервера. Теперь в случае падения (недоступности) сервера, загрузить на новые сервер необходимо только недоступные данные. Все остальные хеши не меняют свое местоположение, то есть консистентны. При добавлении нового сервера соседний разделяет с ним часть своих данных.
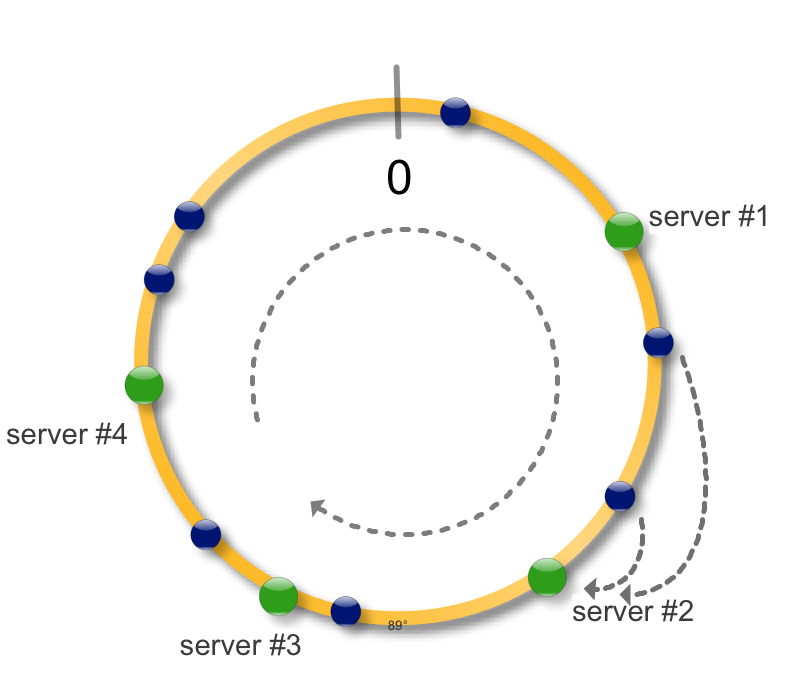
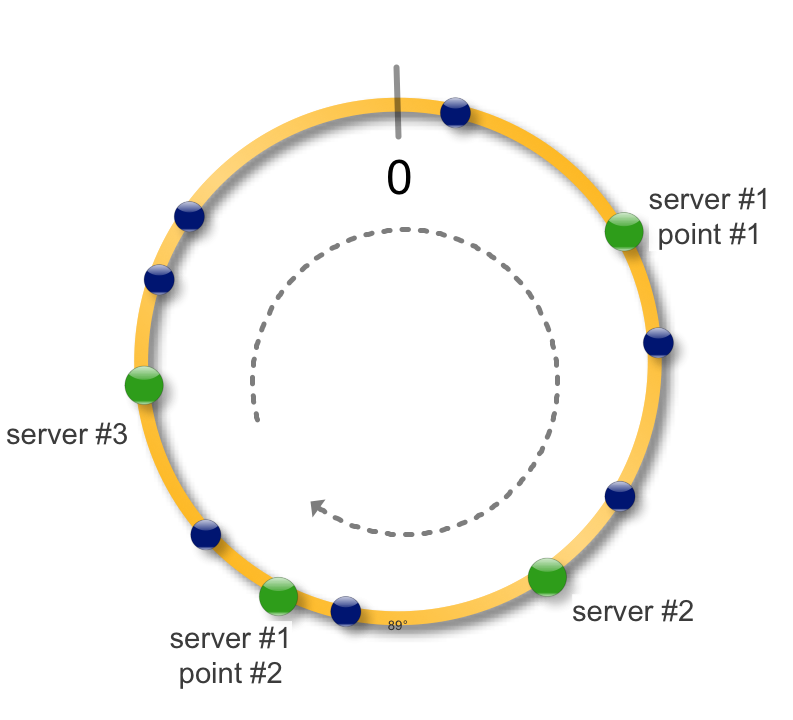
На практике также применяют следующий трюк. Сервер можно пометить на окружности не одной точкой, а несколькими. Что это дает ? - более равномерное распределение данных по серверам - при падении сервера данные распределяются не на один соседний, а на несколько, распределяя тем самым нагрузку - при добавлении нового сервера, точки можно делать активными - постепенно одна за другой, предотвращая шквальную нагрузку на сервер - если конфигурация серверов отличается, например размером диска, количество данных можно контролировать числом его точек. Больше точек - большая длина окружности принадлежит этому серверу и соответственно больше данных.
Для реализации храним хеши серверов в виде какого-либо дерева, например Red-Black. Операция поиска сервера по ключу будет занимать O(log n).
Дополнительно:
- http://dyagilev.org/blog/2012/03/23/consistent-hashing/