Redis
Redis (REmote DIctionary Server) — это нереляционная высокопроизводительная СУБД. Быстрое хранилище данных в памяти с открытым исходным кодом для использования в качестве базы данных, кэша, брокера сообщений или очереди. Redis хранит все данные в памяти, доступ к данным осуществляется только по ключу. Опционально копия данных может храниться на диске. Этот подход обеспечивает производительность, в десятки раз превосходящую производительность реляционных СУБД, а также упрощает шардинг данных.
Интересная особенность Redis заключается в том, что это — однопоточный сервер. Такое решение сильно упрощает поддержку кода, обеспечивает атомарность операций и позволяет запустить по одному процессу Redis на каждое ядро процессора. Разумеется, каждый процесс будет прослушивать свой порт. Решение нетипичное, но вполне оправданное, так как на выполнение одной операции Redis тратит мало времени - порядка одной стотысячной секунды
Типы данных
Строки (strings)
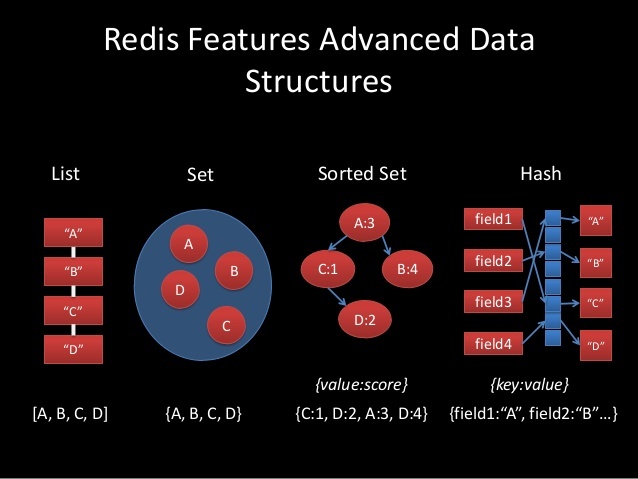
Базовый тип данных Redis. Строки в Redis бинарно-безопасны, могут использоваться так же как числа, ограничены размером 512 Мб. Строки — это основная структура. Это одна их четырех базовых структур, а так же основа всех сложных структур, потому что Список — это список строк, Множество — это множество строк, и так далее.
Строки хороши во всех очевидных сценариях использования, когда вы хотите хранить HTML страницу, но так же они хороши если вы хотите избежать конвертирования уже закодированных данных. Например, если у вас есть JSON или MessagePack, вы можете просто хранить объекты как строки. В Redis 2.6 вы даже можете управлять этим видом структур на стороне сервера, используя скрипты на Lua.
Другое интересное использование строк — это битовые массивы, и вообще, случайный доступ к массивам байтов, так как Redis предоставляет команды доступа к произвольным диапазонам байтов, или даже к отдельным битам.
Списки (lists)
Классические списки строк, упорядоченные в порядке вставки, которая возможна как со стороны головы, так и со стороны хвоста списка. Максимальное количество элементов — 2^32 — 1. Списки хороши когда в основном вы работаете с крайними элементами: около хвоста, или около головы. Списки не лучший выбор для деления чего-либо на страницы, из-за медленного случайного доступа, O(N). Хорошим использованием списков будут простые очереди и стеки, или циклическая обработка элементов командой RPOPLPUSH, параметрами которой будет один и тот же список. Списки так же хороши, когда нам нужна ограниченная коллекция из N элементов, доступ в которой обычно осуществляется только к верхнему или нижнему элементам, или когда N небольшое.
Множества(sets)
Множества строк в математическом понимании: не упорядочены, поддерживают операции вставки, проверки вхождения элемента, пересечения и разницы множеств. Максимальное количество элементов — 2^32 — 1. Множество — это не упорядоченный набор данных, оно эффективно когда у вас есть коллекция элементов, и важно очень быстро проверить присутствие элемента в коллекции, или получить ее размер. Еще одна «фишка» множеств — это возможность получить случайный элемент.
Множества поддерживают сложные операции, такие как пересечение, объединение и так далее, это хороший способ использовать Redis в «вычислительной» манере, когда у вас есть данные, и вы хотите получить некоторый результат, выполняя преобразования над этими данными. Небольшие множества кодируются очень эффективным способом.
Множества используются для хранения уникальных значений и предоставляют набор операций — таких, как объединение. Множества не упорядочены, но предоставляют эффективные операции со значениями. Список друзей является классическим примером использования множеств:
sadd friends:leto ghanima paul chani jessica
sadd friends:duncan paul jessica alia
Независимо от того, сколько друзей имеет пользователь, мы можем эффективно (O(1)) определить, являются ли пользователи userX и userY друзьями, или нет.
sismember friends:leto jessica
sismember friends:leto vladimir
Более того, мы можем узнать, имеют ли два пользователя общих друзей:
sinter friends:leto friends:duncan
и даже сохранить результат этой операции под новым ключом:
sinterstore friends:leto_duncan friends:leto friends:duncan
Множества отлично подходят для теггинга и отслеживания любых других свойств, для которых повторы не имеют смысла (или там, где мы хотим использовать операции над множествами, такие как пересечение и объединение).
Упорядоченные множества(sorted sets)
Упорядоченное множество отличается от обычного тем, что его элементы упорядочены по особому параметру «score». Упорядоченное Множество — это единственная структура данных, кроме списка, поддерживающая работу с упорядоченными элементами. С упорядоченными множествами можно делать много крутых вещей. Например, вы можете реализовать все виды Топа Чего-либо в вашем веб-приложении. Топ пользователей по рейтингу, топ постов по числу просмотров, топ чего угодно, и один экземпляр Redis будет обслуживать тонны вставок и запросов в секунду.
Упорядоченные множества, как и обычные множества, могут быть использованы для описания отношений, но они так же позволят делить элементы на страницы, и сохранять порядок. К примеру, если я храню друзей пользователя X как упорядоченное множество, я могу легко хранить их в порядке добавления в друзья.
Упорядоченные множества хороши для очередей с приоритетами.
Упорядоченные множества — это что-то вроде более мощных списков, в которых вставка, удаление или получение элементов из середины списка так же быстро. Но они используют больше памяти, и являются O(log(N)) структурами.
Упорядоченные множества — симбиоз обычных множеств и списков. Дело в том, что они содержат только уникальные значения, но каждому значению соответствуют число (score). В результате для это типа данных вводится порядок:
A > B, если A.score > B.score если A.score = B.score, то A и B упорядочиваются в соответствии с лексикографическим порядком значений. Так как они уникальны, равенство двух различных элементов в упорядоченном множестве невозможно.
Хеш-таблицы
Хеш-таблицы (hashes). Классические хеш-таблицы или ассоциативные массивы. Максимальное количество пар «ключ-значение» — 2^32 — 1. Хэши отличная структура для представления объектов, составленных из полей и значений. Поля хэшей могут быть атомарно инкрементированы командой HINCRBY. Если у вас есть объекты, такие как пользователи, записи в блоге, или другие виды элементов, хэши — это то, что вам нужно, если вы не хотите использовать свой собственный формат, такой как JSON или любой другой.
Хеши — хороший пример того, почему называть Redis хранилищем пар ключ-значение не совсем корректно. Хеши во многом похожи на строки. Важным отличием является то, что они предоставляют дополнительный уровень адресации данных — поля (fields). Эквивалентами команд set и get для хешей являются:
hset users:goku powerlevel 9000
hget users:goku powerlevel
Мы также можем устанавливать значения сразу нескольких полей, получать все поля со значениями, выводить список всех полей и удалять отдельные поля:
hmset users:goku race saiyan age 737
hmget users:goku race powerlevel
hgetall users:goku
hkeys users:goku
hdel users:goku age
Как вы видите, хеши дают чуть больше контроля, чем строки. Вместо того чтобы хранить данные о пользователе в виде одного сериализованного значения, мы можем использовать хеш для более точного представления. Преимуществом будет возможность извлечения, изменения и удаления отдельных частей данных без необходимости читать и записывать все значение целиком. Однако, имейте в виду, что небольшие хэши в Redis кодируются очень эффективно, и вы можете использовать атомарные операции GET, SET или атомарно инкрементировать отдельное поле с большой скоростью.
Bitmaps
Bitmaps are not an actual data type, but a set of bit-oriented operations defined on the String type. Since strings are binary safe blobs and their maximum length is 512 MB, they are suitable to set up to 232 different bits. Bit operations are divided into two groups: constant-time single bit operations, like setting a bit to 1 or 0, or getting its value, and operations on groups of bits, for example counting the number of set bits in a given range of bits (e.g., population counting).
One of the biggest advantages of bitmaps is that they often provide extreme space savings when storing information. For example in a system where different users are represented by incremental user IDs, it is possible to remember a single bit information (for example, knowing whether a user wants to receive a newsletter) of 4 billion of users using just 512 MB of memory.
HyperLogLog
Redis имеет специальное хранилище HyperLogLog. Оно позволяет сохранять туда ключи, а затем получать количество уникальных ключей в этом хранилище. Ограничение в том, что список сохраненных ключей достать невозможно. Преимущество в том, что одно такое хранилище занимает всего 12 Кб, способно сохранять 264 элементов и возвращает результат с погрешностью всего 0.8%.
Streams
Redis Stream — новый абстрактный тип данных, представленный в Redis с выходом версии 5.0 Концептуально Redis Stream — это List, в который вы можете добавлять записи. Каждая запись имеет уникальный идентификатор. По умолчанию идентификатор генерируется автоматически и включает в себя временную метку. Поэтому вы можете запрашивать диапазоны записей по времени или получать новые данные по мере их поступления в поток, как Unix команда «tail -f» читает лог-файл и замирает в ожидании новых данных. Обратите внимание, что поток могут слушать одновременно несколько клиентов, как многие «tail -f» процессы могут одновременно читать файл, не конфликтуя друг с другом.
- Сообщение доставляется одному клиенту. Первый заблокированный чтением клиент получит данные первым.
- Клинт должен сам инициировать операцию чтения каждого сообщения. List ничего не знает о клиентах.
- Сообщения хранятся до тех пор, пока их кто-то не считает или не удалит явно. Если вы настроили Redis сервер, чтобы он сбрасывал данные на диск, то надёжность системы резко возрастает.
Псевдо-Многоключевые Запросы
Типичной ситуацией, в которую вы будете попадать, будет необходимость запрашивать одно и то же значение по разным ключам. Например, вы можете хотеть получить данные пользователя по адресу электронной почты (в случае, если пользователь входит на сайт впервые) и по идентификатору (после входа пользователя на сайт). Одним из ужасных решений будет дублирование объекта в двух строковых значениях:
set users:leto@dune.gov "{id: 9001, email: 'leto@dune.gov', ...}"
set users:9001 "{id: 9001, email: 'leto@dune.gov', ...}"
Это неправильно, поскольку такими данными трудно управлять, и они занимают в два раза больше памяти.
Было бы здорово, если бы Redis позволял создавать связь между двумя ключами, но такой возможности нет (и скорее всего никогда не будет). Главным принципом развития Redis является простота кода и API. Внутренняя реализация связанных ключей (есть много вещей, которые можно делать с ключами, о чем мы еще не говорили) не стоит возможных усилий, если мы увидим, что Redis уже предоставляет решение — хеши.
Используя хеш, мы можем избавиться от необходимости дублирования:
set users:9001 "{id: 9001, email: leto@dune.gov, ...}"
hset users:lookup:email leto@dune.gov 9001
Мы используем поле как вторичный псевдо-индекс, и получаем ссылку на единственный объект, представляющий пользователя. Чтобы получить пользователя по идентификатору, мы используем обычную команду get:
get users:9001
Чтобы получить пользователя по адресу электронной почты, мы воспользуемся сначала hget, а затем get (код на Ruby):
id = redis.hget('users:lookup:email', 'leto@dune.gov')
user = redis.get("users:#{id}")
Это то, чем вы, скорее всего, будете пользоваться очень часто. Для меня это как раз тот случай, когда хеши особенно хороши, но это не очевидный способ использования, пока вы не увидите это своими глазами.
Хранение
Redis хранит данные в оперативной памяти, но периодически сохраняет их на диск, чтобы восстановить при перезапуске. Стандартные настройки сделаны для скорости, а не надежности, поэтому при перезапуске часть данных теряется. Но есть возможность писать данные на диск. Цена — резкая деградация производительности. Есть 4 режима:
- RDB (Redis Database): The RDB persistence performs point-in-time snapshots of your dataset at specified intervals.
- AOF (Append Only File): The AOF persistence logs every write operation received by the server, that will be played again at server startup, reconstructing the original dataset. Commands are logged using the same format as the Redis protocol itself, in an append-only fashion. Redis is able to rewrite the log in the background when it gets too big.
- No persistence: If you wish, you can disable persistence completely, if you want your data to just exist as long as the server is running.
- RDB + AOF: It is possible to combine both AOF and RDB in the same instance. Notice that, in this case, when Redis restarts the AOF file will be used to reconstruct the original dataset since it is guaranteed to be the most complete.
RDB-snapshot
Полный слепок всех данных. Устанавливается с помощью конфигурации SAVE X Y и читается как «Сохранять полный снепшот всех данных каждые X секунд, если изменилось хотя бы Y ключей». Самый простой способ делать резервные копии данных. Благодаря сжатию, которые можно включить в конфиге, занимает гораздо меньше места, чем на диске AOF. Представляет собой единый файл, который обновляется периодически автоматически, если в конфиге указан параметр SAVE, или при необходимости с помощью команд SAVE или BGSAVE.
RDB — это очень компактное однофайловое представление ваших данных Redis на определенный момент времени. Файлы RDB идеально подходят для резервного копирования. Например, вы можете захотеть архивировать файлы RDB каждый час в течение последних 24 часов и сохранять моментальный снимок RDB каждый день в течение 30 дней. Это позволяет легко восстанавливать разные версии набора данных в случае аварий.
RDB максимизирует производительность Redis, поскольку единственная работа, которую должен выполнить родительский процесс Redis для сохранения, — это разветвление дочернего процесса, который сделает все остальное. Родительский процесс никогда не будет выполнять дисковый ввод-вывод или что-то подобное.
RDB позволяет быстрее перезапускать большие наборы данных по сравнению с AOF.
На репликах RDB поддерживает частичную повторную синхронизацию после перезапуска и отработки отказа.
Минусы
RDB НЕ подходит, если вам нужно свести к минимуму вероятность потери данных в случае, если Redis перестанет работать (например, после отключения электроэнергии). Вы можете настроить различные точки сохранения, в которых создается RDB (например, после как минимум пяти минут и 100 операций записи в набор данных у вас может быть несколько точек сохранения). Однако вы обычно создаете моментальный снимок RDB каждые пять минут или чаще, поэтому в случае, если Redis перестанет работать без корректного завершения работы по какой-либо причине, вы должны быть готовы потерять последние минуты данных.
RDB необходимо часто выполнять fork(), чтобы сохраняться на диске с помощью дочернего процесса. fork() может занимать много времени, если набор данных большой, и может привести к тому, что Redis перестанет обслуживать клиентов на несколько миллисекунд или даже на одну секунду, если набор данных очень большой, а производительность процессора невысокая. AOF также нуждается в fork(), но реже, и вы можете настроить, как часто вы хотите переписывать свои журналы без какого-либо компромисса в отношении долговечности.
AppendOnlyFile
список операций в порядке их выполнения. Добавляет новые пришедшие операции в файл каждые Х секунд или каждые Y операций. Для AOF можно настроить политики fsync: каждую секунду, на каждый запрос или вообще ничего не делать. Благодаря тому, что при использовании AOF Redis по умолчанию пишет данные на диск каждую секунду, максимум, что вы теряете в случае сбоя при использовании этого режима — это 1 секунда. Redis может автоматически перезаписывать AOF-файл, если он становится слишком большим. Но у AOF тоже есть недостатки.
Обычно файлы AOF гораздо больше по размеру, чем аналогичный файл RDB, при том же наборе данных. AOF может быть медленнее, чем RDB на запись, в зависимости от настроек fsync. Кроме того, даже в случае большой нагрузки на запись RDB лучше ведет себя в плане задержек.
RDB +AOF
Комбинация двух предыдущих.
В любом случае Redis — не высоконадежное хранилище данных, а быстрая легкая база для данных, которые нестрашно потерять.
TTL
Redis позволяет назначать ключам срок существования. Вы можете использовать абсолютные значения времени в формате Unix (Unix timestamp, количество секунд, прошедших с 1 января 1970 года) или оставшееся время существования в секундах. Эта команда оперирует ключами, поэтому неважно, какая структура данных при этом используется.
expire pages:about 30
expireat pages:about 1356933600
Первая команда удалит ключ (и ассоциированное с ним значение) по истечении 30 секунд. Вторая сделает то же самое в 12:00, 31 декабря 2012 года
По умолчанию все данные хранятся вечно.
Транзакции
Как и все остальное, реализованы просто и обеспечивают атомарное выполнение набора команд. Изоляции нет, но в Redis она и не нужна, так как Redis — однопоточное приложение, и транзакции не выполняются параллельно.
Репликация
Реализована как master-slave: на мастер можно писать и читать, слейвы — только чтение. Настраивается легко, работает безотказно. Репликация с несколькими главными серверами не поддерживается. Каждый подчиненный сервер может выступать в роли главного для других. Репликация в Redis не приводит к блокировкам ни на главном сервере, ни на подчиненных. На репликах разрешена операция записи. Когда главный и подчиненный сервер восстанавливают соединение после разрыва, происходит полная синхронизация (resync).
Redis поддерживает репликацию, которая означает, что все данные, которые попадают на один узел Redis (который называется master) будут попадать также и на другие узлы (называются slave). Для конфигурирования slave-узлов можно изменить опцию slaveof или выполнить аналогичную по написанию команду (узлы, запущенные без подобных опций являются master-узлами).
PubSub
Позволяет клиентам подписываться на обновления ключей. На основе этого можно построить систему обмена сообщениями, например.
Redis Cluster
Был добавлен в Redis v.3.0, и является полноценным native решением для создания и управления кластером с сегментацией и репликаций данных. Выполняет задачи управления нодами, репликации, синхронизации данных, обеспечением доступа к ним в случае выхода из строя одного или более мастеров.
- Несколько мастер-инстансов, у каждого один или более слейвов (до 1000).
- Выполняет все задачи по шардингу, репликации, failover, синхронизации данных.
- Требует как минимум 6 нод Reedis-а: три для мастеров, и три для слейвов.
- Умеет перенаправлять запросы от клиентов на нужный мастер или слейв — но это требует поддержки кластера самими клиентами Redis.
Сегментация
Кластер не использует консистентное хеширование, вместо этого используется так называемые hash-slots. Весь кластер имеет 16384 слотов, для вычисления хэш-слота для ключа используется формула crc16(key) % 16384. Каждый узел Redis отвечает за конкретное подмножество хэш-слотов, например:
- Узел A содержит хеш-слоты от 0 до 5500.
- Узел B содержит хеш-слоты от 5501 до 11000.
- Узел C содержит хеш-слоты от 11001 до 16383.
Это позволяет легко добавлять и удалять узлы кластера. Если мы добавляем узел D, то можно просто переместить некоторые хеш-лоты других узлов. Если же удаляем A, то нам необходимо постепенно переместить все хэш-слоты узла А на другие, а когда хэш-слотов не останется, то просто удалить узел из кластера. Всё это выполняется постепенно командами, нам не нужно приостанавливать выполнение операций, не нужно пересчитывать процентное соотношение хеш-слотов к количеству узлов, никаких прочих остановок системы.
Возникает вопрос - Redis имеет сложные структуры данных с составными ключами, ведь хэш-функция посчитает для них разные значения? Имеется и ответ:
- Составные ключи одной команды, одной транзакции или одного скрипта Lua, гарантировано попадут в один хэш-слот.
- Пользователь может принудительно сделать составные ключи частью одного хэш слота с помощью концепта хэш-тегов.
Если вкратце, то хэш-теги говорят Redis что именно хешировать, цель хэширования задается в фигурных скобках. Так, хэши этих ключей будут равны - foo.{key}.bar и baz.{key}.biz.
Репликация
Каждый хэш-слот имеет от 1 (master) до N (N-1 slave) реплик. Таким образом, если выйдет из строя некоторый слот, то кластер назначит его slave master-ом.
Дополнительно: